ORACLE DB 함수 정리
함수
1. DUAL 테이블
SELECT 절에 기술할 테이블이 없을 경우 사용
간혹 10+30 결과를 보는 등 쿼리 작업에서 연산식만 사용하는 경우가 있는데
실행되려면 테이블 값이 꼭 들어가야 하므로 더미 테이블을 사용하는 것
기존에 사용하는 테이블을 사용하면 해당 테이블의 행 만큼 출력되어 버림
SQL> select 10+30 from dept;
10+30
----------
40
40
40
40
SQL> select 10+30 from dual;
10+30
----------
40
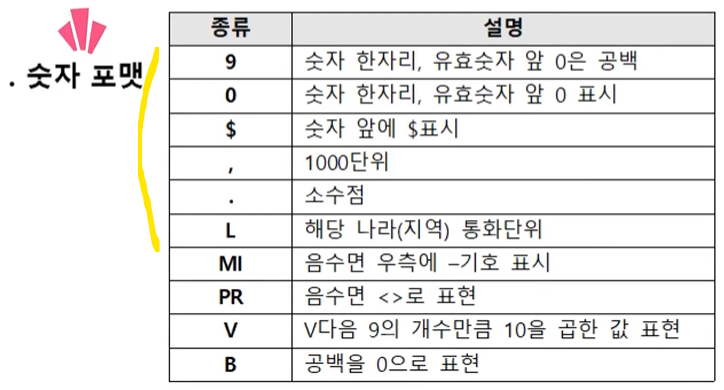
2. 숫자 처리 함수
ROUND (반올림) 함수
지정한 자리 수 이하에서 반올림한 결과를 구해주는 함수
ROUND(숫자, 반올림자리수)

-
반올림 방법
- 반올림자리(N)가 0 또는 양수이면 N+1 위치에서 반올림
- 반올림자리가 음수이면 N 위치에서 반올림
SQL> select round(46.592, 0) from dual; ROUND(46.592,0) --------------- 47 SQL> select round(46.592, 1) from dual; ROUND(46.592,1) --------------- 46.6 SQL> select round(46.592, 2) from dual; ROUND(46.592,2) --------------- 46.59 SQL> select round(46.592, -1) from dual; ROUND(46.592,-1) ---------------- 50 SQL> select round(46.592, -2) from dual; -- 자리값에서 벗어나면 0 출력하는듯 ROUND(46.592,-2) ---------------- 0
TRUNC(버림) 함수
지정한 자리 수 이하에서 버린 결과를 구해주는 함수
TRUNC(숫자, 버림자리수)
-
버림 방법
- 버림자리수도 반올림 자리수와 마찬가지의 방식을 따른다.
SQL> select trunc(46.592, 0) from dual; TRUNC(46.592,0) --------------- 46 SQL> select trunc(46.592, 2) from dual; TRUNC(46.592,2) --------------- 46.59 SQL> select trunc(46.592, -1) from dual; TRUNC(46.592,-1) ---------------- 40
MOD(나머지) 함수
나누기 연산을 한 후 나머지를 결과로 리턴
MOD(컬럼 | 숫자, 나누기값)
SQL> select mod(5, 2) from dual;
MOD(5,2)
----------
1
SQL> select mod(sal, 100) from emp where deptno = 10;
MOD(SAL,100)
------------
50
0
0
3. 문자 처리 함수
UPPER(대문자), LOWER(소문자) 함수
소문자는 대문자로, 대문자는 소문자로 변환해 출력
SQL> select upper('hello'), lower('HELLO') from dual;
UPPER LOWER
----- -----
HELLO hello
SQL> select lower(ename) from emp where ename like '%A%';
LOWER(ENAM
----------
allen
ward
martin
blake
clark
adams
james
INITCAP 함수
단어의 첫글자만 대문자로 변환해 출력
SQL> select initcap('HELLO'), initcap('hello') from dual;
INITC INITC
----- -----
Hello Hello
SQL> select initcap(ename) from emp where ename like '%A%';
INITCAP(EN
----------
Allen
Ward
Martin
Blake
Clark
Adams
James
LENGTH 함수
문자열의 길이를 구하여 출력
SQL> select length('hellohello') from dual;
LENGTH('HELLOHELLO')
--------------------
10
SQL> select ename, length(ename) from emp;
ENAME LENGTH(ENAME)
---------- -------------
SMITH 5
ALLEN 5
WARD 4
JONES 5
MARTIN 6
BLAKE 5
CLARK 5
SCOTT 5
KING 4
TURNER 6
ADAMS 5
ENAME LENGTH(ENAME)
---------- -------------
JAMES 5
FORD 4
MILLER 6
14 rows selected.
INSTR 함수
특정 컬럼 또는 문자열에서 지정 문자의 위치를 반환
검색 문자 순서를 생략하면 첫번째로 발견한 검색문자를 반환
검색 시작 위치를 생략하면 처음부터 검색
INSTR(컬럼 | 문자열, 컬럼 | 문자열, [검색할 시작위치], [반환할 검색문자 순서])
-- 'welcome to oracle'의 첫번째부터 소문자 'o'를 검색
select instr('welcome to oracle', 'o') from dual;
INSTR('WELCOMETOORACLE','O')
----------------------------
5
-- 'welcome to oracle'의 6번째부터 소문자 'o'를 검색
select instr('welcome to oracle', 'o', 6) from dual;
INSTR('WELCOMETOORACLE','O',6)
------------------------------
10
-- 'welcome to oracle'의 3번째부터 3번째로 검색된 소문자 'o'를 검색
select instr('welcome to oracle', 'o', 3, 3) from dual;
INSTR('WELCOMETOORACLE','O',3,3)
--------------------------------
12
SUBSTR 함수
특정 컬럼 또는 문자열에서 지정한 일부분을 추출해 반환
SUBSTR(컬럼 | 문자열, 시작위치, [추출문자 개수])
SQL> select substr('welcome to oracle', 4, 3) from dual;
SUB
---
com
SQL> select substr('welcome to oracle', 10) from dual;
SUBSTR('
--------
o oracle
LPAD, RPAD 함수
오른쪽(왼쪽) 정렬 후 지정 문자를 왼쪽(오른쪽)에 채우는 함수
LPAD(컬럼 | 문자열, 자리수, '채울문자')
SQL> select lpad('oracle', 10, '*'), rpad('database', 10, '*') from dual;
LPAD('ORAC RPAD('DATA
---------- ----------
****oracle database**
SQL> select lpad('morning', 16, '#%') from dual;
LPAD('MORNING',1
----------------
#%#%#%#%#morning
LTRIM, RTRIM 함수
왼쪽(오른쪽) 지정 문자가 연속이면 지정 문자를 삭제
LTRIM(컬럼 | 문자열, '삭제문자');
SQL> select ltrim('****oracle', '*'), rtrim('oracle****', '*') from dual;
LTRIM( RTRIM(
------ ------
oracle oracle
SQL> select ltrim('****ora**cle**', '*') from dual;
LTRIM('***
----------
ora**cle**
TRIM 함수
양쪽에 지정 문자가 연속이면 지정 문자를 삭제
trim('삭제할문자' from '문자열')
SQL> select trim('*' from '****ora**cle*****') from dual;
TRIM('*'
--------
ora**cle
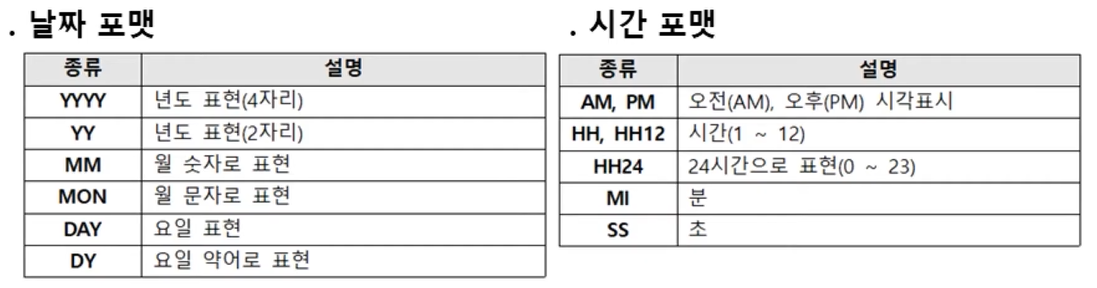
4. 날짜 처리 함수
대부분 일 단위로 계산
SYSDATE 함수
시스템에 저장된 현재 날짜와 시간을 반환
SYSDATE+1(내일 날짜),SYSDATE-1(어제 날짜)
SQL> select sysdate from dual;
SYSDATE
---------
15-APR-20
SQL> select sysdate+1 from dual;
SYSDATE+1
---------
16-APR-20
SQL> select sysdate-1 from dual;
SYSDATE-1
---------
14-APR-20
-- 20번 부서 사원들의 현재까지 근무 일수를 출력
SQL> select ename, hiredate, sysdate-hiredate "근무일수" from emp where deptno = 20;
ENAME HIREDATE 근무일수
---------- -------- ----------
SMITH 80/12/17 14364.8731
JONES 81/04/02 14258.8731
SCOTT 87/04/19 12050.8731
ADAMS 87/05/23 12016.8731
FORD 81/12/03 14013.8731
SQL> select ename, hiredate, trunc(sysdate-hiredate, 0) "근무일수" from emp where deptno = 20;
ENAME HIREDATE 근무일수
---------- -------- ----------
SMITH 80/12/17 14364
JONES 81/04/02 14258
SCOTT 87/04/19 12050
ADAMS 87/05/23 12016
FORD 81/12/03 14013
MONTHS_BETWEEN 함수
날짜와 날짜 사이의 개월 수를 구하는 함수
MONTHS_BETWEEN(최근날짜, 이전날짜)
SQL> select ename, hiredate, months_between(sysdate, hiredate) from emp;
ENAME HIREDATE MONTHS_BETWEEN(SYSDATE,HIREDATE)
---------- -------- --------------------------------
SMITH 80/12/17 471.963657
ALLEN 81/02/20 469.866883
WARD 81/02/22 469.802367
JONES 81/04/02 468.447528
MARTIN 81/09/28 462.608818
BLAKE 81/05/01 467.479786
CLARK 81/06/09 466.221722
SCOTT 87/04/19 395.899141
KING 81/11/17 460.963657
TURNER 81/09/08 463.25398
ADAMS 87/05/23 394.770109
ENAME HIREDATE MONTHS_BETWEEN(SYSDATE,HIREDATE)
---------- -------- --------------------------------
JAMES 81/12/03 460.41527
FORD 81/12/03 460.41527
MILLER 82/01/23 458.770109
14 행이 선택되었습니다.
ADD_MONTHS 함수
지정한 개월 수를 더한 날짜를 구하는 함수
ADD_MONTHS(날짜, 더할 개월 수)
SQL> select sysdate, add_months(sysdate, 12) from dual;
SYSDATE ADD_MONT
-------- --------
20/04/15 21/04/15
SQL> select hiredate, add_months(hiredate, 6) from emp where deptno = 20;
HIREDATE ADD_MONT
-------- --------
80/12/17 81/06/17
81/04/02 81/10/02
87/04/19 87/10/19
87/05/23 87/11/23
81/12/03 82/06/03
LAST_DAY 함수
해당 날짜가 속한 달의 마지막 날짜를 반환
LAST_DAY(날짜)
SQL> select hiredate, last_day(hiredate) from emp where deptno = 20;
HIREDATE LAST_DAY
-------- --------
80/12/17 80/12/31
81/04/02 81/04/30
87/04/19 87/04/30
87/05/23 87/05/31
81/12/03 81/12/31
NEXT_DAY 함수
해당 날짜 이후로 명시된 요일에 해당되는 날짜를 반환
요일 파라미터에는
‘월’, ‘화’, ‘MON’, ‘TUE’, 1(일), 2(월), 3(화) 등 사용 가능
NEXT_DAY(날짜, 요일)
select next_day(sysdate, '월') from dual;
5. 데이터형 변환 함수
숫자, 문자, 날짜의 데이터형을 변환해야 하는 경우 사용
TO_NUMBER 함수 # 문자 → 숫자
TO_NUMBER('숫자문자열')
SQL> select to_number('15522') from dual;
SQL> select to_number('1444') + 1 from dual;
TO_NUMBER('1444')+1
-------------------
1445
TO_CHAR 함수 # 숫자|날짜 → 문자
TO_CHAR(숫자|날짜, 형별포맷)
select to_char(sysdate, 'YYYY/MM/DD HH24:MI:SS DAY') from dual;
select to_char(sal, 'L999,999') from emp where deptno = 20;
TO_DATE 함수 # 문자 → 날짜
DATE형은 날짜와 시간을 포함한다
TO_DATE(문자열, 해당문자열의 날짜 포맷)
select to_date('2020-01-20', 'YYYY-MM-DD') from dual;
select to_date('2020-1월-20', 'YYYY-MON-DD') from dual;
select to_date('20-1월-20', 'YY-MON-DD') from dual;
6. 기타 함수
NVL 함수
NVL(컬럼, 변환값)
NULL이 있으면 0 또는 다른 값으로 변환
SQL> select empno, comm from emp;
EMPNO COMM
---------- ----------
7369
7499 300
7521 500
7566
7654 1400
7698
7782
7788
7839
7844 0
7876
EMPNO COMM
---------- ----------
7900
7902
7934
14 행이 선택되었습니다.
SQL> select empno, nvl(comm, 0) from emp;
EMPNO NVL(COMM,0)
---------- -----------
7369 0
7499 300
7521 500
7566 0
7654 1400
7698 0
7782 0
7788 0
7839 0
7844 0
7876 0
EMPNO NVL(COMM,0)
---------- -----------
7900 0
7902 0
7934 0
14 행이 선택되었습니다.
DECODE 함수
SWITCH CASE 와 유사
마지막에 비교값 없이 처리값만 넣으면 else 처럼 동작. (즉 기본값)
DECODE(표현식|컬럼명, 비교1, 처리1, 비교2, 처리2, ...)
-- deptno 값을 보고 그에 맞는 문자열 출력
select ename, deptno, decode(deptno,
10, '회계',
20, '영업',
30, '마케팅',
40, '경영') "부서명"
from emp;
ENAME DEPTNO 부서명
---------- ---------- ---------------------------
SMITH 20 영업
ALLEN 30 마케팅
WARD 30 마케팅
JONES 20 영업
MARTIN 30 마케팅
BLAKE 30 마케팅
CLARK 10 회계
SCOTT 20 영업
KING 10 회계
TURNER 30 마케팅
ADAMS 20 영업
ENAME DEPTNO 부서명
---------- ---------- ---------------------------
JAMES 30 마케팅
FORD 20 영업
MILLER 10 회계
-- 기본값 테스트
select ename, deptno, decode(deptno,
10, '회계',
20, '영업',
'테스트') "부서명"
from emp;
ENAME DEPTNO 부서명
---------- ---------- ---------------------------
SMITH 20 영업
ALLEN 30 테스트
WARD 30 테스트
JONES 20 영업
MARTIN 30 테스트
BLAKE 30 테스트
CLARK 10 회계
SCOTT 20 영업
KING 10 회계
TURNER 30 테스트
ADAMS 20 영업
ENAME DEPTNO 부서명
---------- ---------- ---------------------------
JAMES 30 테스트
FORD 20 영업
MILLER 10 회계
CASE 함수
DECODE 함수는 값이 같을때만 가능
CASE 함수는 다양한 비교 연산 가능
select ename, deptno,
case
when deptno = 10 then '회계'
when deptno = 20 then '마케팅'
when deptno = 30 then '영업'
when deptno = 40 then '경영'
end "부서명"
from emp;
ENAME DEPTNO 부서명
---------- ---------- ---------------------------
SMITH 20 마케팅
ALLEN 30 영업
WARD 30 영업
JONES 20 마케팅
MARTIN 30 영업
BLAKE 30 영업
CLARK 10 회계
SCOTT 20 마케팅
KING 10 회계
TURNER 30 영업
ADAMS 20 마케팅
ENAME DEPTNO 부서명
---------- ---------- ---------------------------
JAMES 30 영업
FORD 20 마케팅
MILLER 10 회계
14 행이 선택되었습니다.
select ename, job, case
when job = 'CLERK' then sal + (sal * 0.2)
when job = 'ANALYST' then sal + (sal * 0.15)
when job = 'MANAGER' then sal + (sal * 0.1)
else sal
end "salary"
from emp;
7. 그룹 함수
전체 데이터를 그룹별로 구분해 통계적인 결과를 구할 때 사용
기본 select 쿼리 절에서는 그룹함수와 단순 컬럼 함께 사용 불가
SQL> select max(sal), ename from emp;
select max(sal), ename from emp
*
1행에 오류:
ORA-00937: 단일 그룹의 그룹 함수가 아닙니다
단일행 함수
입력 데이터를 하나씩 처리하는 함수
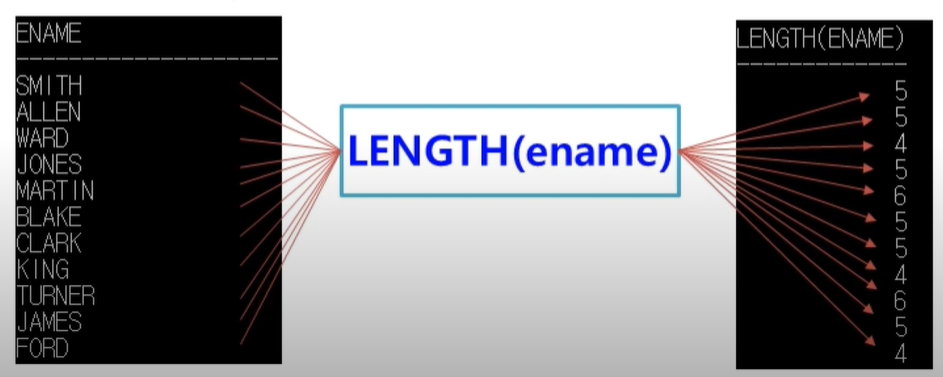
select length(ename) from emp;
LENGTH(ENAME)
-------------
5
5
4
5
6
5
5
4
6
5
4
LENGTH(ENAME)
-------------
6
다중행 함수
입력 데이터를 한 번에 처리해 나오는 결과값이 하나

select count(ename) from emp;
COUNT(ENAME)
------------
12
SUM 함수
지정한 컬럼 값들의 총합을 구하는 함수 (Null 제외)
select sum(sal) from emp;
SUM(SAL)
----------
24925
AVG 함수
지정한 컬럼 값들의 평균을 구함
select round(avg(sal), 1) "평균급여" from emp;
AVG(SAL)
----------
2077.08333
MAX, MIN 함수
지정한 컬럼 값들의 최대값, 최소값을 구함
문자, 날짜 데이터에도 사용 가능 (사전상 빠른 문자열, 오래된 날짜가 Min)
select min(sal) "최소급여", max(sal) "최대급여" from emp;
최소급여 최대급여
---------- ----------
800 5000
select min(ename), max(ename), min(hiredate), max(hiredate) from emp;
MIN(ENAME) MAX(ENAME) MIN(HIRE MAX(HIRE
---------- ---------- -------- --------
ALLEN WARD 80/12/17 82/01/23
COUNT 함수
테이블 전체 또는 컬럼의 총 행의 갯수를 출력 (Null 제외)
select count(*) from sometable; -- 테이블의 총 행의 갯수 반환
select count(col) from sometable; -- 해당 컬럼의 총 행의 갯수 반환
select count(comm) from emp; -- 널 값이 있는 행은 제외됨
COUNT(COMM)
-----------
4
GROUP BY 절
전체 데이터를 그룹별로 나눠 정렬해줌
GROUP BY 절을 사용하면 해당 그룹 함수와 함께 해당 컬럼을 같이 select 해 사용 가능
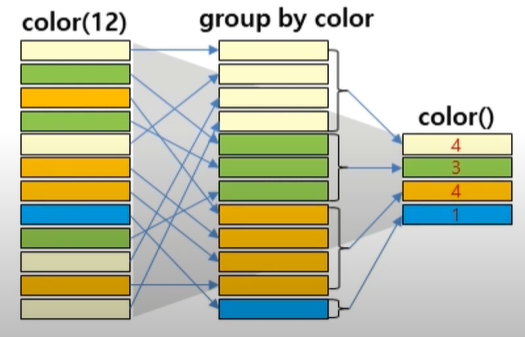
SQL> select deptno, avg(sal) from emp group by deptno;
DEPTNO AVG(SAL)
---------- ----------
30 1566.66667
10 2916.66667
20 2258.33333
SQL> select deptno, count(*), count(comm) from emp group by deptno;
DEPTNO COUNT(*) COUNT(COMM)
---------- ---------- -----------
30 6 4
10 3 0
20 3 0
SQL> select job, count(*), avg(sal) from emp group by job;
JOB COUNT(*) AVG(SAL)
--------- ---------- ----------
CLERK 3 1016.66667
SALESMAN 4 1400
ANALYST 1 3000
MANAGER 3 2758.33333
PRESIDENT 1 5000
HAVING 절
GROUP BY 절에 의해 생성된 결과 중 원하는 조건을 만족하는 데이터만 출력
WHERE 절에는 그룹함수를 사용할 수 없음
SQL> select deptno, avg(sal) from emp group by deptno having avg(sal) >= 2000;
DEPTNO AVG(SAL)
---------- ----------
10 2916.66667
20 2258.33333
-- 급여를 1000이상 받는 사원들의 평균 급여가 2000이상인 부서의 번호와 부서별 평균 급여 출력
SQL> select deptno, avg(sal) from emp where sal>=1000 group by deptno having avg(sal)>=2000;
DEPTNO AVG(SAL)
---------- ----------
10 2916.66667
20 2987.5